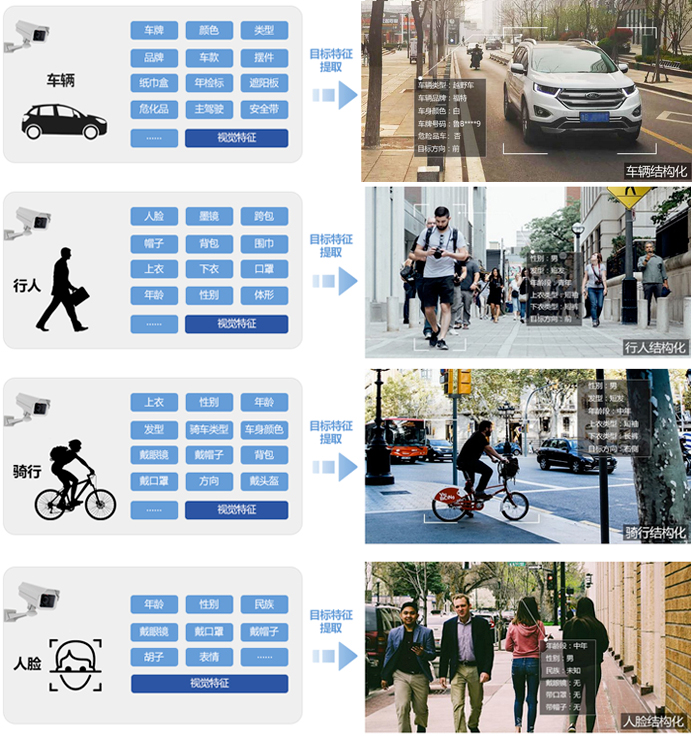
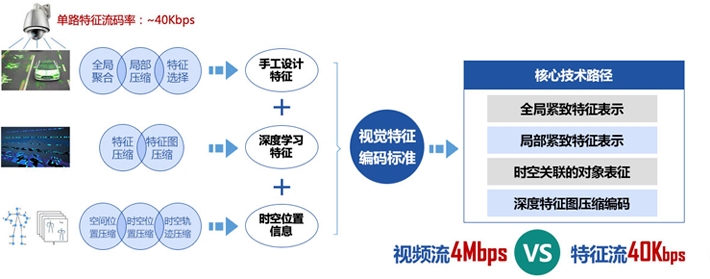
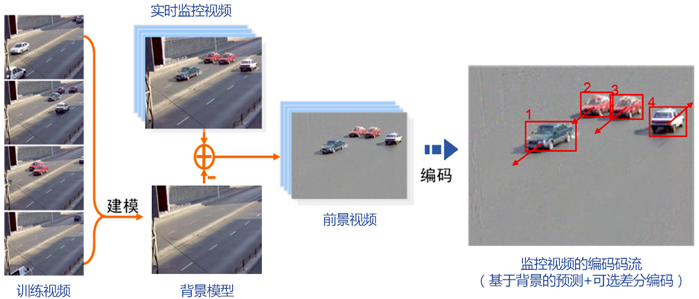
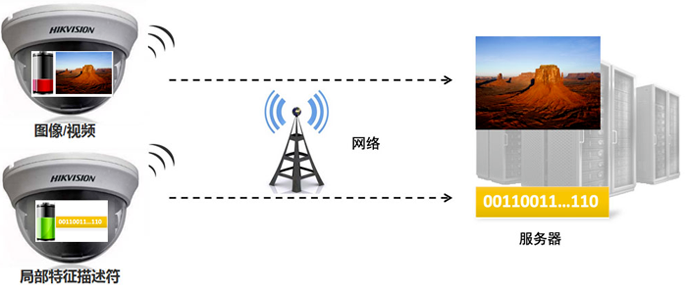
双流编码联合优化 采用通用的编码技术标准;针对广播电视视频,采用混合编码框架,压缩比每十年翻一番;AVS2场景编码;从消除背景冗余入手,提出基于背景模型的场景视频编码框架针对固定场景监控视频,压缩比达~600:1。