
- 数据视网膜
- 大数据云脑
全目标视频结构化
实现复杂视频监控场景下对行人、机动车、骑行、人脸四类关键目标的精准识别,并提供动态检测与跟踪、特征提取、结构化属性分类等。

车牌
颜色
类型
品牌
车款
摆件
纸巾盒
年检标
遮阳板
危化品
主驾驶
安全带
......
视觉特征
目标特征提取


车辆

人脸
墨镜
跨包
帽子
背包
围巾
上衣
下衣
口罩
年龄
性别
体形
......
视觉特征
目标特征提取

行人

上衣
性别
年龄
发型
骑车类型
车身颜色
戴眼镜
戴帽子
背包
戴口罩
方向
戴头盔
......
视觉特征
目标特征提取

骑行

年龄
性别
民族
戴眼镜
戴口罩
戴帽子
胡子
表情
......
视觉特征
目标特征提取

人脸
融合紧凑特征表达
采用大规模场景下业内最优的融合特征表达、压缩技术,相比原图压缩率达1%,存储降低100倍,带宽成本降低100倍,显著减少数据传输延迟。

-
全局
聚合局部
压缩特征
选择 手工设计
手工设计
特征 - +
-
特征
压缩特征图
压缩深度学习
特征 - +
-
空间位
置压缩时空位
置压缩时空轨
迹压缩时空位置
信息
视觉特征
编码标准
编码标准
核心技术路径
全局紧致特征表示
局部紧致特征表示
时空关联的对象表征
深度特征图压缩编码
视频流
 特征流
特征流
特征流
单路特征流码率:~40Kbps
基于背景模型的场景视频编码
采用通用的编码技术标准;针对广播电视视频,采用混合编码框架,压缩比每十年翻一番;AVS2场景编码;从消除背景冗余入手,
提出基于背景模型的场景视频编码框架针对固定场景监控视频,压缩比达~600:1。
提出基于背景模型的场景视频编码框架针对固定场景监控视频,压缩比达~600:1。

实时监控视频
训练视频
背景模型
前景视频
监控视频的编码码流
(基于背景的预测+可选差分编码)
(基于背景的预测+可选差分编码)

双流编码联合优化
面向高效的传输和恢复;损失图像纹理信息。
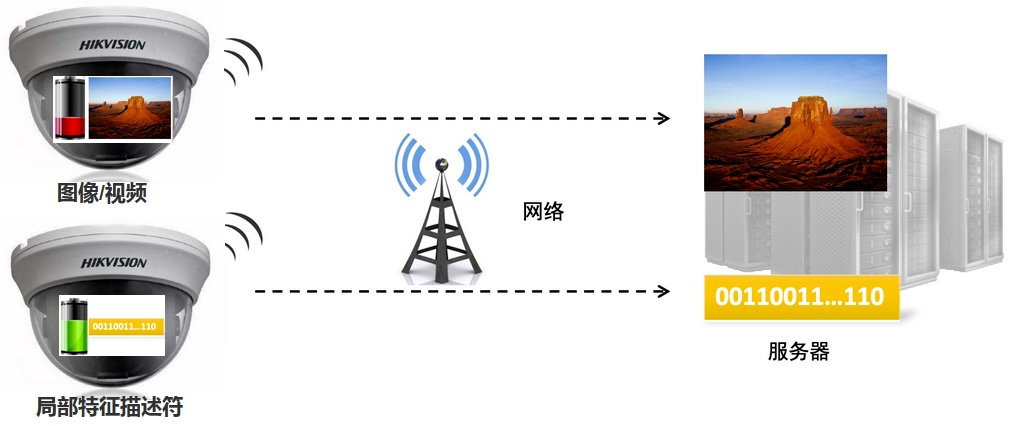
超大规模视觉特征高效索引
采用全局特征“粗筛选”+局部特征“细排序”的分布式架构,实现百亿级图像中100ms内返回目标结果,相比主流水平检索速度提高100倍。

跨时空对象重检追踪与识别
采用同视域内追踪、跨视域再标识技术,实现跨时空对象重检追踪与识别,相对传统模式,人车跨镜追踪平均准确率达到80%以上。
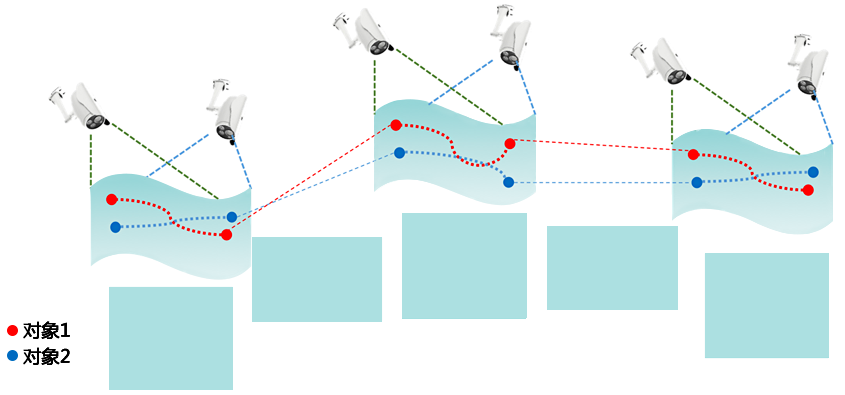
跨时间、跨场景下的行人、车辆追踪
- 同视域内追踪
- 粒子滤波、集成追踪、核化相关滤波;构造多对象间关系网络图
- 跨视域再标识
- 迁移学习+深度学习,多子空间关联模型:
-

- 同视域内追踪
- 粒子滤波、集成追踪、核化相关滤波;构造多对象间关系网络图
- 跨视域再标识
- 迁移学习+深度学习,多子空间关联模型:
-
- 同视域内追踪
- 粒子滤波、集成追踪、核化相关滤波;构造多对象间关系网络图
核心技术路径
大视域多对象追踪
跨视域行人再标识
多线索身份识别
视频大数据处理支撑平台
采用异构GPU-CPU分布式并行计算架构、统一资源存储管理,支持千亿级图像和十万路视频流的超大规模分析处理。
系统平台服务
任务发布&状态监控

数据查询与展示
前端设备资源接入
原始视频流

服务发现&资源管理
算法仓库系统
算法资源库
计算资源调度
算法服务调度
服务发现
任务调度
负载均衡
- 算法资源管理
-

- 任务调度管理
-
异构分布式计算分析资源池
边缘设备计算节点
物理服务器节点
虚拟服务器节点
节点资源监控
节点应用管理
结构化属性&矢量特征
终端数据接入
数据中转服务
管理调度服务

云端高性能索引系统
索引融合应用
结构化数据索引
高性能矢量特征索引
视频关键帧索引
流式视频数据&目标快照数据


存储资源池
海量分布式文件存储
分布式流式视频存储
分布式特征数据存储
核心技术路径
异构GPU-CPU分布式并行计算架构
资源统一存储、管理与调度
接入数据标准规范与技术验证数据库
城市知识图谱
采用群智推理的模型对知识进行推理修正、精炼和再加工,构建百万规模的群智计算知识图谱,实现对交通和安全态势评估与预测。


博云视觉(北京)科技有限公司
博云视觉科技(青岛)有限公司
 010-5940-3220
010-5940-3220
 地址:北京市海淀区中关村软件园二期未名视通研发楼303室(北京)
地址:北京市海淀区中关村软件园二期未名视通研发楼303室(北京)
山东省青岛市崂山区科苑纬一路1号青岛国际创新园G座2005


关注博云

Copyright © 2015-2020 博云视觉(北京)科技有限公司 京ICP备16004185号-1